Innehållsförteckning
Detta är en gammal version av dokumentet!
Komma igång med miner
Översikt
Efter installationen av miner hamnar du på en översiktlig vy.
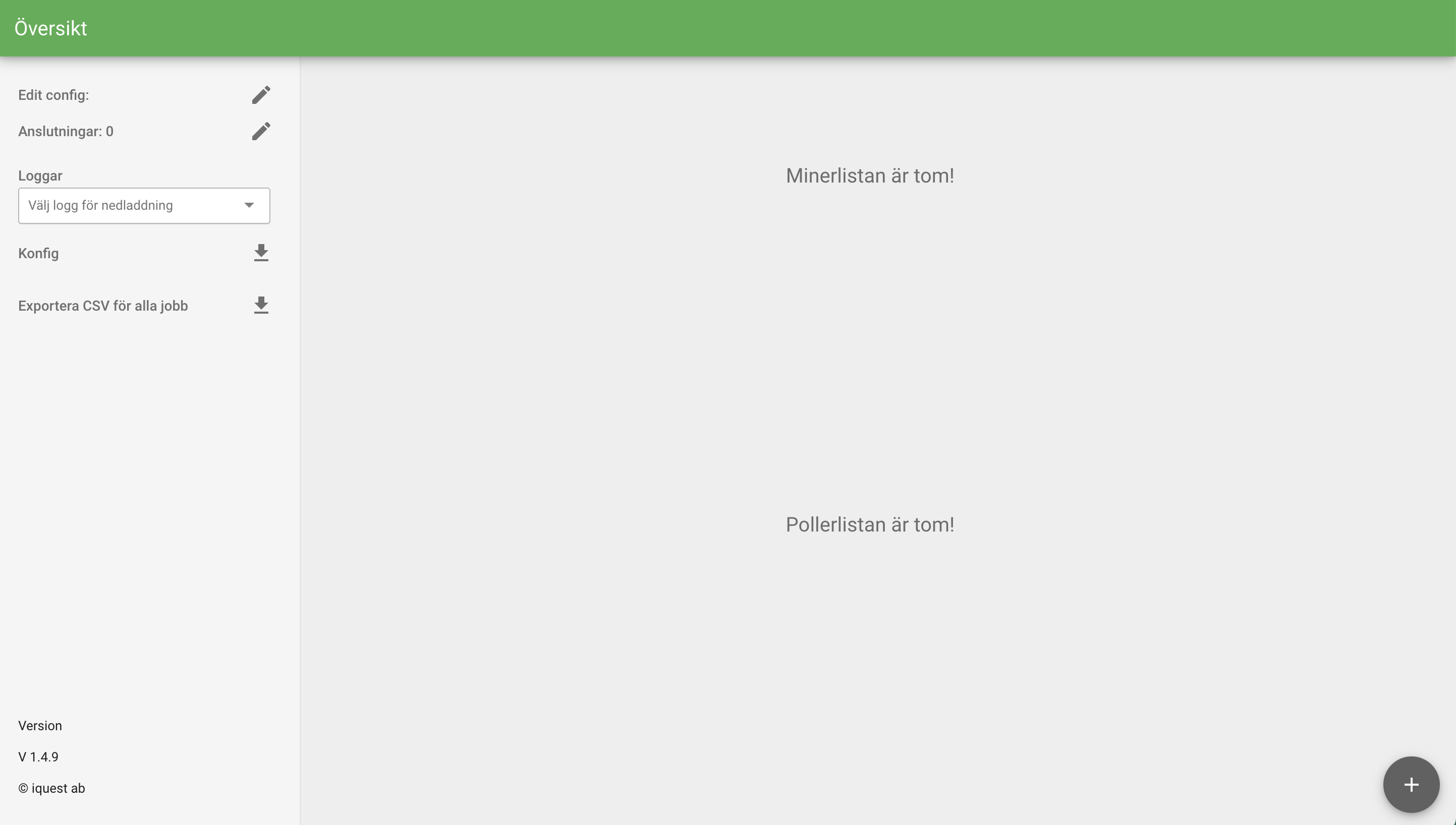 }
När miner startas läser den in Jobb och Anslutningar. Därefter listas alla Jobb som rader i tabellen.
Via den vänstra panelen får se och redigera minerns grundkonfiguration, anslutningar, samt ladda ned loggfiler och ta backup av minerns konfiguration.
}
När miner startas läser den in Jobb och Anslutningar. Därefter listas alla Jobb som rader i tabellen.
Via den vänstra panelen får se och redigera minerns grundkonfiguration, anslutningar, samt ladda ned loggfiler och ta backup av minerns konfiguration.
Använd gärna backupfunktionen ofta, exempelvis innan du påbörjar förändring eller uppdatering av ett jobbs inställningar. Backupfunktionen laddar ned en kopia av minerns inställningar som en zip-fil, som du kan spara på ditt system. Om du behöver återställa en backup, behöver du just nu hjälp av oss på iquest. Vi planerar att införa en återställningsfunktion i kommande versioner av miner.
Anslutningar
Du kan skapa nya anslutningar genom att klicka på plusknappen längst ned till höger på översiktssidan och därefter välja alternativet ”Anslutning”. Du kan även klicka på pennsymbolen uppe till vänster på översiktssidan, till höger om rubriken ”anslutningar”. Därefter startar en guide som låter dig välja typ av anslutning och ange nödvändiga uppgifter med hjälp av ett formulär som skiljer sig åt beroende av vald anslutningstyp.
Om du vill redigera befintliga anslutningar, får du gå via den vänstra panelen och pennsymbolen till höger om rubriken ”Anslutningar”.
Jobb
Nya jobb konfigureras genom att klicka på plussymbolen nere till höger på översiktssidan.
Redigering av befintliga jobb sker genom att först stoppa jobbet via översiktssidan, och därefter klicka på jobbet och därefter klicka sig in i jobbet för att göra ändringar och justeringar, genom att klicka på tabellraden för jobbet på översiktssidan.
Glöm inte att starta jobbet igen, efter att ha gjort dina ändringar.
I miner skiljer vi mellan fyra typer av jobb. Idag redovisas jobb av typen Poller för sig, medan Miner och Exporter visas i samma tabell. I kommande versioner av miner, kommer samtliga jobb att visas via en och samma tabell och jobbtyperna ”Miner” och ”Poller” kommer successivt att bakas ihop i smarta generella Jobb som kombinerar funktionerna hos ”Miner” och ”Poller”, beroende av de möjligheter som finns hos datakällan.
Miner
Vissa datakällor har egna databaser med historiklagring och tillåter bulkhämtningar av data. Med en bulkhämtning (eller batchhämtning) menas att minern kan koppla upp sig vid valfri tidpunkt och fråga efter all data som har lagrats i datakällan sedan senaste hämtningen. Förutsatt att datakällan (exempelvis ett överordnat styrsystem) kontinuerligt lagrar data från anslutna system (exempelvis DUC/PLC), så kan en minerinstans som körs inom ett annat nätverk (exempelvis inom en molnmiljö), koppla upp sig med jämna mellanrum och ladda över önskat urval av data som har lagrats inom datakällan.
Dylika jobb, som kan hämta bulkdata, kallar vi för ”miners”. Vi är medvetna om att det kan uppstå viss förvirring eftersom själva produkten också kallas för miner
Poller
Om datakällan inte har en egen databas, alternativt inte har stöd för bulkhämtning av data, kan minern kontinuerligt och enligt inställda intervaller, läsa av varje datapunkt, bygga en egen databas samt ladda över dataavläsningarna till Orbiq. Vi pratar då om att plocka ”polla” datapunkterna i jobbet. I anslutning till varje körcykel, går miner igenom samtliga datapunkter och läser av värden från datakällan i enlighet med inställd intervall. I pollerjobb finns det möjlighet att anpassa läsfrekvens och sparintervall med hjälp av följande inställningar som kan anges för var och en av datapunkterna i ett jobb.
poll_interval_sec: Pollningsintervall
Anger hur ofta data ska läsas från datapunkten. Anges i hela sekunder.
cov: ChangeOfValue
Anger hur stor förändringen av datapunktens värde ska vara, i relation till det senast sparade värdet, för att nytt värde ska sparas. Kan anges i decimalformat (OBS! Använd punkt som decimaltecken) om cov anges via import/export av CSV-filer.
minimal_save_interval: Största "hålet" mellan två sparade avläsningar i databasen
Anger maxtiden som ska gå mellan två sparade värden och anges i sekunder. minimal_save_interval rekommenderas att anges, om ni väljer att använda ChangeOfValue. Tänk er exempelvis, att en poller läser av statusen för en pumps driftindikering, där pumpen är i drift i flera dygn. Om vi inte använder ”minimal_save_interval” tillsammans med ”cov”, så kommer miner endast att spara värden när pumpen slås på/av. I en visualisering som endast visar den senaste veckan, kommer då driftindikeringen att se ut att sakna data.
Exporter
Exporterjobb är en typ av Minerjobb, där dataströmmen går åt motsatt håll. Data hämtas då från Orbiq och skickas till en extern datakälla.
Writer
Jobb av typen Writer kan integreras i andra jobb, där miner stödjer skrivning till den aktuella datakällan.
För att kunna skriva till datakällan behöver datapunkten i första hand vara överskrivningsbar, vissa integrationer visar detta som en tagg och till vissa integrationer behöver man logga in på datakällan för att se vilka datapunkter som är överskrivningsbara.
För varje datapunkt som ska skrivas över så kan Miner hantera minimum- och maximumgränser, prioritet för överskrivning, varaktighet och själva värdet som ska skrivas till datakällan. Som värde kan man välja att sätta en konstant eller hämta ett värde från en annan datapunkt inom samma Miner.
Miner stödjer i dagsläget enbart en CSV-importering för att skapa skrivpunkter. Enklaste sättet att skapa CSV-filen är att ladda ned filen overwrite-template.zip och packa upp den.
overwrite-template.rar
Öppna sedan CSV-filen i den textredigeraren du föredrar, exempelvis Microsoft Excel eller Notepad. Öppna/spara gärna i UTF-8 om möjligt.
 Du borde få något liknande som på bilden ovan.
Varje rad i CSV-filen kan ses som en överskrivningsregel. Följande är en beskrivning för varje kolumn i CSV-filen:
Du borde få något liknande som på bilden ovan.
Varje rad i CSV-filen kan ses som en överskrivningsregel. Följande är en beskrivning för varje kolumn i CSV-filen:
- target: Datapunkten som vi ska skriva till.
- minValue: Minimumgränsen som ”value” kan ha för att överskrivningsregeln ska bli giltig.
- maxValue: Maximumgränsen som ”value” kan ha för att överskrivningsregeln ska bli giltig.
- prio: Ordningen för överskrivningsregeln. Ju högre siffra desto högre prioritet.
- duration: Varaktigheten för överskrivningen. Om datakällan har stöd för en varaktighet vid överskrivning skickas ”duration” till datakällan för att meddela om hur länge vi vill att värdet ska vara giltigt. Om datakällan inte har stöd för varaktighet används ”duration” tillsammans med ”minValue” och ”maxValue” för att se om ”value” ska skrivas till datapunkten.
- value: Värdet som ska skrivas till ”target”. Vi kan ange antingen en konstant eller värdet från en befintlig datapunkt i samma Miner.
När vi vet vad varje kolumn betyder kan vi börja lägga till rader:

<uuid.1> ska självklart bytas ut till UUID för datapunkten som man vill överskriva. I exemplet ovan ser vi att ”minValue” är satt till 0 och ”maxValue” till 10, ”prio” är satt till 15, ”duration” till 30m (30 minuter) och ”value” är 4. Med denna rad säger vi till Miner att
För datapunkten <uuid.1> ska vi sätta värdet 4 i 30m om värdet är mellan 0 och 10.
Detta är den mer enkla implementationen av en överskrivningsregel, det kan göras lite mer komplicerade regler:

Här har vi lagt till en regel och ändrat föregående regel så att den hamnar utanför ”minValue” och ”maxValue”.
Reglerna säger nu följande:
Om värdet 11 är mellan 0 och 10 ska vi skriva värdet till datapunkten <uuid.1> och ska vara giltig i 30m, annars ska värdet 5 skrivas till <uuid.1> och vara giltigt i 30m om värdet är mellan 0 och 10.
I exemplet ovan är det alltså ”prio” som sätter ordningen för överskrivningsreglerna. Lägger man till fler regler för samma datapunkt men med lägre prio blir det som en ”fallback”.
Vi kan även lägga till fler datapunkter att skriva till:

Observera att ”prio” limiteras till varje unika ”target”, i exemplet ovan gäller fortfarande samma prioritering för de två reglerna med <uuid.1>. Den nya raden med <uuid.2> får sin egna gruppering med ”prio”.
För att visa en bredare funktionalitet kan vi göra på följande sätt:

Här har vi gjort om regeln för <uuid.2> så att den hämtar en tagg från en annan datapunkt och sätter det som ”minValue” och ”maxValue”, i exemplet har vi tagit helt ologiska taggar; meterkey och fastighet. Vi tog också ett värde från en annan datapunkt. Observera att vi behöver ha '[' i början och ']' i slutet när vi refererar till en datapunkt. Datapunkten måste existera inom Minern.
När du känner dig klar med CSV-filen behöver den sparas i UTF-8 (kontrollera att det inte finns några tomma rader), vi kan därefter gå tillbaka till jobbet som har alla datapunkter som du har definierat i ”target”. Klicka på plus-ikonen längst ned till höger och välj sedan ”Importera skrivpunkter från CSV”.

Välj sedan den CSV-fil som du precis sparat och följ stegen tills du kommer tillbaka till jobbet.
Du kan kontrollera de datapunkter som du satte en överskrivning på genom att trycka på den, du bör få en panel på höger sida med datapunktens detaljer. Om det ser liknande ut som på bilden nedan så har allt gått bra, du kan nu starta jobbet. Det kan vara bra att även kontrollera i datakällan om värden faktiskt skrivs till rätt punkt.

Quality Stamp (qstamp)
Varje värde för en datapunkt skickas med en stämpel som informerar om kvalitén på värdet. Nedan listas samtliga qstamps som skickas med avläsningarna:
0: unknown 1: good 2: bad, sending interpolated value 3: bad, sending null 4: bad, sending last good value 5: good, overwritten value